Javier Chávarri
About
Performance Of Records In BuckleScript
April 12, 2018
BuckleScript is a compiler backend, created by Hongbo Zhang, that allows to build apps using Reason or OCaml code, and produces clean, performant JavaScript code. Performance is one of the core values behind the project, and looking at the implementation one can see many different techniques that are used to pursue that goal.
I was recently surprised by the way it compiles immutable records. Or rather, how performant this compiled output can be, given the optimizations that BuckleScript applies to the output code. In this article, we will see the output JavaScript code produced by the compiler given some examples, plus a few benchmarks of update operations, comparing with some alternatives.disclaimer
We will be using Reason for the code examples, which BuckleScript accepts as input syntax (as well as OCaml).

Using the platform
BuckleScript compiles records as JavaScript arrays, so if we have a file Car.re written in Reason like:
type car = {
id: string,
year: int,
model: string,
};
let superCar = {
id: "1",
year: 2005,
model: "Not a Tesla"
};It gets compiled into Car.bs.js:
var superCar = /* record */[
/* id */"1",
/* year */2005,
/* model */"Not a Tesla"
];The types aren’t needed or valid in JavaScript, so they disappear. And besides the “property names as comments” –added there as a devexp measure and removable through minification– the previous record becomes just a plain ol’ JavaScript array.
Records are also immutable, so if we try to do something like:
/* In Car.re */
superCar.model = "Tesla";We will get a nice compilation error from BuckleScript saying The record field 'id' is not mutable. Cool! Having immutable data structures provided by the compiler / language toolchain is useful and avoids the need to add external dependencies to your project.
Record updates
Now, let’s say we want to have a function that creates a “Tesla” version of every car. Something like this, in Car.re:
let pimpMyRide = car => {
...car,
model: "Tesla"
};Gets compiled into this in Car.bs.js:
function pimpMyRide(car) {
return /* record */ [
/* id */ car[/* id */ 0],
/* year */ car[/* year */ 1],
/* model */ "Tesla"
];
}Note there is no slice or concat, BuckleScript “unwraps” the array into its fully fledged shape, reads the values that remain the same from the original array (car[0] and car[1]) and sets the new value ("Tesla") in the key to update (model).
What I didn’t know is that this “array unwrap” technique is much faster than any other alternative out there. More on this just next.
Edit, 04/13/18: as Richard Feldman pointed out on Twitter, Elm uses a similar technique to unwrap records, but it generates objects instead of arrays, which seems to be slightly faster. The downside being a bundle size increase to account for the record fields names, but there is ongoing work to mitigate that too.
Comparing record update solutions
To evaluate the performance of this BuckleScript approach to record updates, we can compare it with two available functions:
Object.assignArray.slice(actuallyslice(0)as it’s more performant)
The results from this setup are available in this online test, and here is a visualization for those in a rush, for an Intel(R) Core(TM) i7–4870HQ CPU @ 2.50GHz running Chrome 65.0.3325.181:
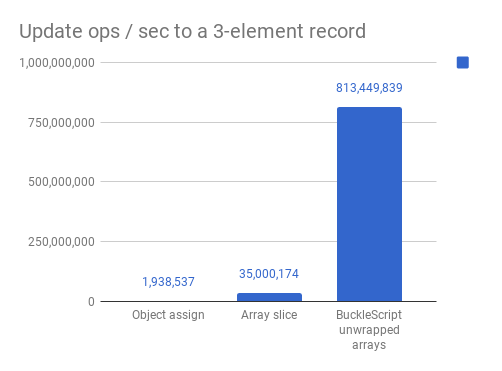
Should have been called RocketScript
Depending on the size of the record, and a ton of other factors –variability of the input data, shape of the properties,…– the difference between cases might change. If you want to know more, Benedikt Meurer explains in this great post why polymorphism kicks in when Object.assign is used like in the benchmark above.
Besides these particularities, for the purpose of this exploration let’s just say… omgunwrappedarraysarecrazyfasssstttttt!!!! 🏇
Large records
Now you must be thinking: “this doesn’t scale, if you have very large records, the read operations from the original array for each position might start piling up, plus the generated code will become massively large because for each updater function”. And you’d be right! The output code and “bundle tax” could become a problem.
Luckily BuckleScript has this issue covered as well. When records start being too large (≥21 keys, as of 04/12/18), the compiler will make use of slice(0) for updates to the records. See the compiled output of the up function in this example. Now try to remove one property and see what happens. ✨
Read operations
We have focused only on write operations. I think a benchmark for read operations using a similar setup like the one above wouldn’t provide that much information, as there isn’t much nuance in reading a property from such small objects, or an index from an array. Both will be very fast and have similar performance. Or at least in regular cases, but things get interesting when the object keys are numbers.
It would be nice to compare read operations with existing immutable libraries too, but I will leave that as an exercise to the reader. 📚
Conclusions
To implement the “record as unwrapped array” technique, BuckleScript needs three things in order to produce this output:
- the fields of the record at compile time
- guarantees that the values of these fields will not change at runtime
- control over the generated code
A compiler-to-JavaScript has this information, so it is in a unique position to provide performant, immutable data structures.
Immutable libraries written in JavaScript on the other hand are only “one npm install away” of any existing web app, but the creators of these libraries have their solution space limited by the much larger flexibility and dynamism that JavaScript objects allow.
Finally, records are just a very small sample of what BuckleScript can provide. Just a few weeks ago, the beta of the new standard library Belt was released. It provides a lot of other data structures, so I’m looking forward to know more about that.
Thanks for reading! And hope you found this interesting. Feel free to add a comment below, or reach on Twitter!
-
I am interested in learning more about performance in order to ship faster products, but I am not an expert in the JavaScript VM internals, or in browser performance. Performance is a field full of nuances and detail, especially when working with engines as complex as the JavaScript one. So do your own research and draw your own conclusions. 🙌
↩